wiki
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
1. 概念
1. 批处理(batch) vs 流处理(stream)
批处理:流处理:
2. 有界流 vs 无界流
有界流:有定义数据流的开始,但没有定义数据流的结束无界流:有定义流的开始,也有定义流的结束
3. 状态
状态:只有在每一个单独的事件上进行转换操作的应用才不需要状态,换言之,每一个具有一定复杂度的流处理应用都是有状态的
4. 时间
时间:许多常见的流计算都基于时间语义,例如窗口聚合、会话计算、模式检测和基于时间的 join
3. API 结构
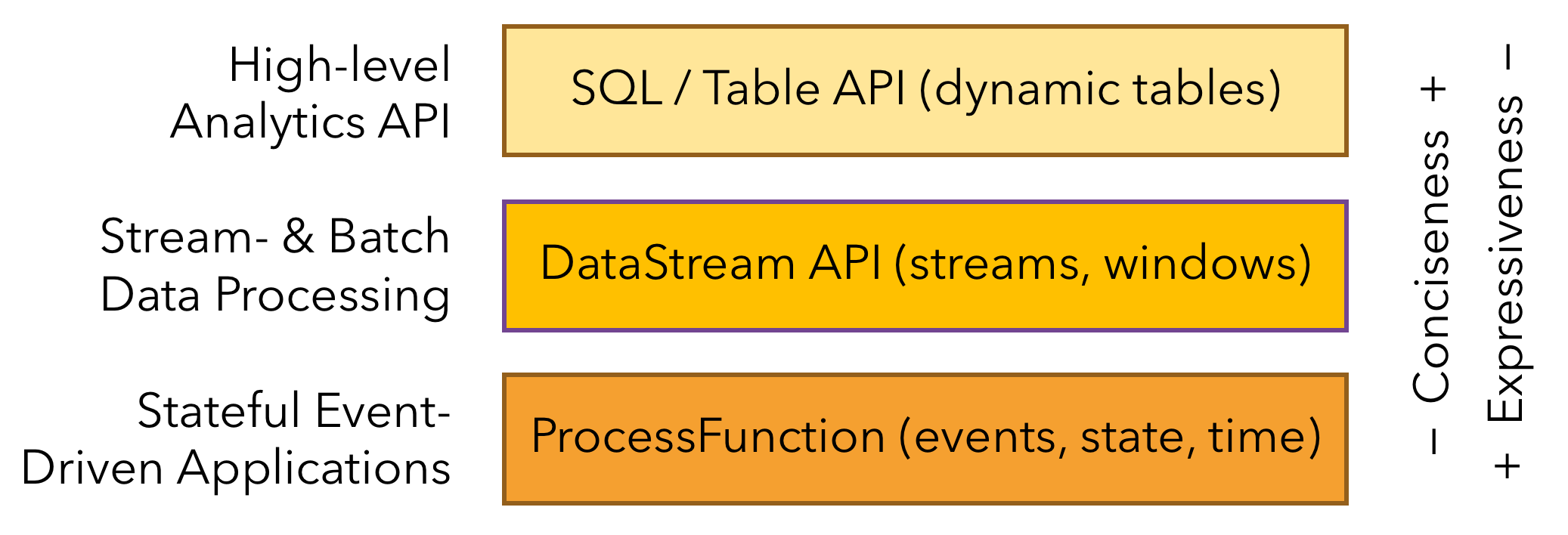
1. ProcessFunction
最底层提供的是有状态的流式计算引擎,流(Stream)、状态(State)和时间(Time)等流式计算概念都在这一层得到了实现
2. DataStream API
应用程序一般使用 Flink 提供的核心API:针对有界和无界数据流的 DataStream API 和针对有界数据集的 DataSet API。用户可以使用这两个API进行常用的数据处理:转换(Transformation)、连接(join)、聚合(Aggregation)、窗口(window)以及对状态(state)的操作。
3. SQL & Table API
在这一层,数据被转换成了关系型数据库式的表格,每个表格拥有一个表模式(Schema),用户可以像操作表格那样操作流式数据,例如可以使用针对结构化数据的select、join、group-by 等操作
3. 集群
1. 总览
一个 Flink 集群总是包含一个 JobManager 以及一个或多个 TaskManager。
JobManager负责处理Job提交、 监控以及资源管理TaskManager运行worker进程,负责实际任务Tasks的执行,而这些任务共同组成了一个Flink Job

