wiki
Flink Transformation 各算子可以对 Flink 数据流进行处理和转化,多个 Transformation 算子共同组成一个数据流图。Transformation 是对数据流进行操作,数据流最常用数据结构是 DataStream,其由多个相同的元素组成,每个元素是一个单独的事件,用泛型来定义。
算子介绍
1. map
map 算子对一个 DataStream 中的每个元素使用用户自定义的 map 函数进行处理,每个输入元素对应一个输出元素,最终整个数据流被转换成一个新的 DataStream。输出的数据流 DataStream<OUT> 类型可能和输入的数据流 DataStream<IN> 不同。
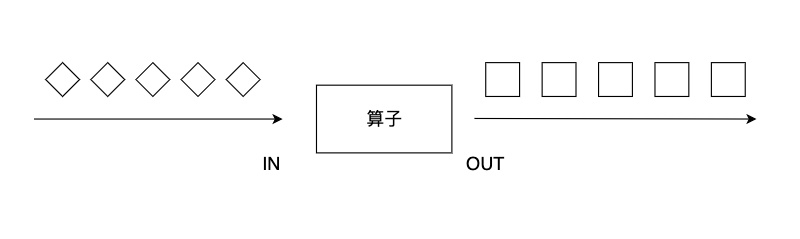
可以重写 MapFunction 或 RichMapFunction 来自定义 map 函数
1 |
|
2. flatMap
flatMap 算子和 map 有些相似,输入都是数据流中的每个元素,与之不同的是,flatMap 的输出可以是零个、一个或多个元素,当输出元素是一个列表时,flatMap 会将列表展平。如下图所示,输入是包含圆形或正方形的列表,flatMap 过滤掉圆形,正方形列表被展平,以单个元素的形式输出。
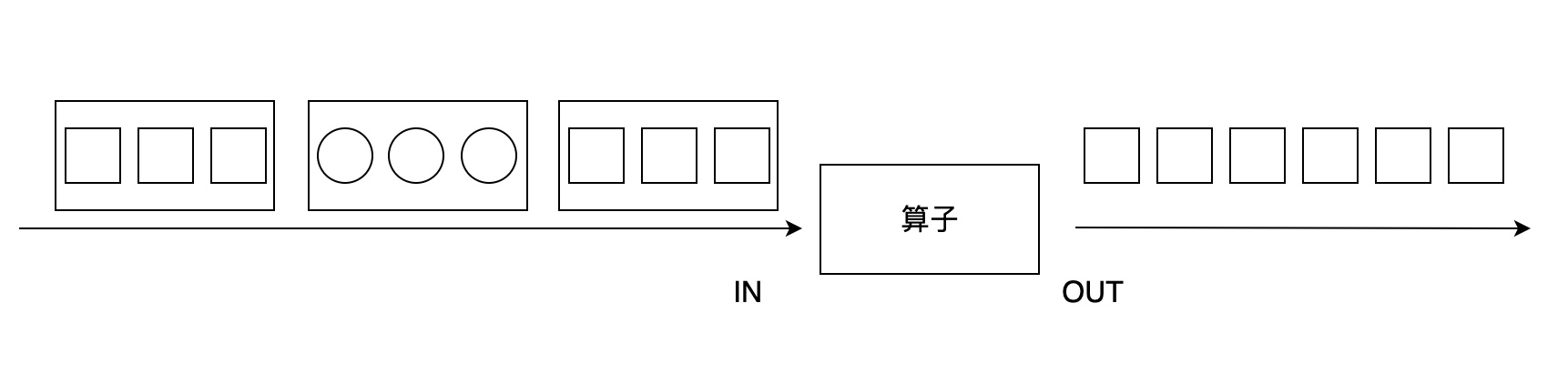
因为 flatMap 可以输出零到多个元素,我们可以将其看做是 map 和 filter 更一般的形式。
虽然 flatMap 可以完全替代 map 和 filter ,但 Flink 仍然保留了这三个API,主要因为 map 和 filter 的语义更明确,更明确的语义有助于提高代码的可读性。map 可以表示一对一的转换,filter 则明确表示发生了过滤操作。
可以重写 FlatMapFunction 或 RichFlatMapFunction 来自定义 flatMap 函数
1 |
|
3. filter
filter 算子对每个元素进行过滤,过滤的过程使用一个 filter 函数进行逻辑判断。对于输入的每个元素,如果 filter 函数返回 True,则保留,否则丢弃。
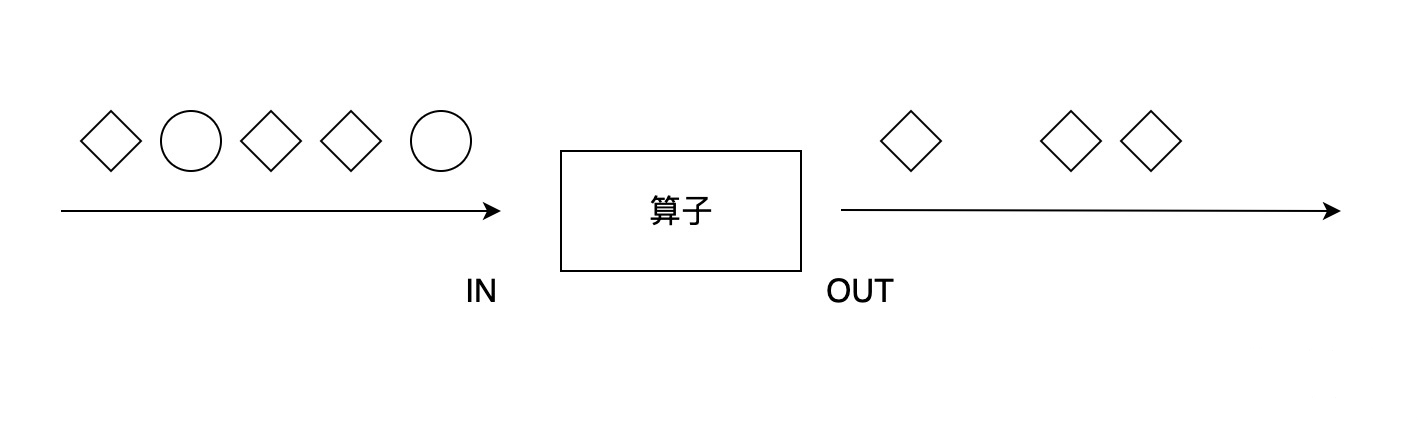
可以继承 FilterFunction 或 RichFilterFunction,然后重写 filter 方法,我们还可以将参数传递给继承后的类
1 |
|
4. 聚合操作算子
4.1. keyBy
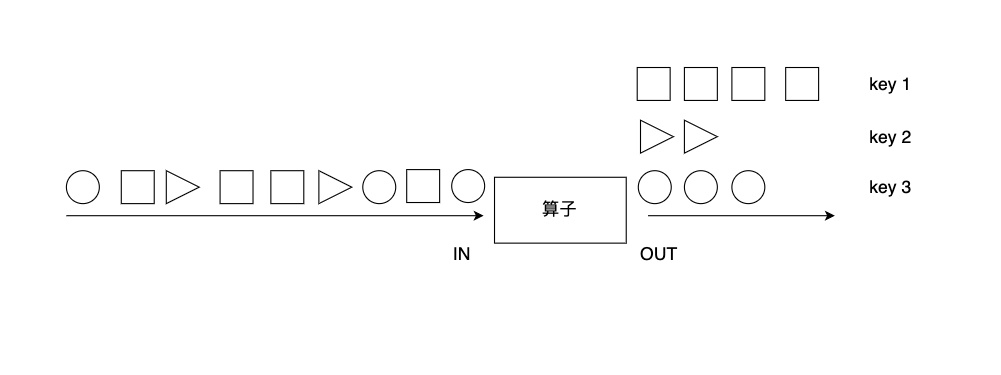
DataStream -> KeyedStream:对数据进行分组,相同形状的元素被分到了一起,可被后续算子统一处理。
前者的各元素随机分布在各Task Slot中,后者的各元素按照Key分组。
1 | DataStream<String> DataStream = ...; |
4.2. 滚动聚合算子
4.2.1. sum
sum 算子的功能对该字段进行加和,并将结果保存在该字段上。
4.2.2. max,maxBy,min,minBy
可以传入数字位置或者字段名。
max算子对该字段求最大值,并将结果保存在该字段上。maxBy求最大值的同时保留其他字段的数值,即maxBy可以得到数据流中最大的元素。- 最小值同理。
1 | KeyedStream<String> keyedStream = ...; |
4.3. reduce
KeyedStream -> DataStream:分组数据流的聚合操作,合并当前元素和上次聚合结果,产生一个新的值,返回流中包含的每一次聚合结果,而不是只返回最后一次聚合结果。
可以继承 ReduceFunction 或 RichReduceFunction,然后重写 reduce 方法,我们还可以将参数传递给继承后的类
1 |
|
5. 多流转换算子
5.1. split,select
split:DataStream -> SplitStream,分流,将一个DataStream转换为多个DataStreamselect:SplitStream -> DataStream,从一个SplitSream获取一个和多个DataStream
1 | DataStream dataStream = ...; |
5.2. connect,map,flatMap
connect:DataStream,DataStream -> ConnectedStreams,连接两个流,但内部依然保持各自数据和形式,两个流相互独立map,flatMap:ConnectedStreams -> DataStream,功能与map和flatMap一样,对其中每一个流分别进行map和flatMap
1 | DataStream<String> selectStream1 = ...; |
5.3. union
DataStream -> DataStream:对两个以上的 DataStream 进行 union 操作,产生一个包含所有元素的流。要求数据类型必须一致。
1 | DataStream<String> unionStream1 = ...; |
