1. wiki
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。通常是指一个更广泛的概念,即 Hadoop 生态圈。
2. 核心组件
1. MapReduce 负责计算
Hadoop 版本的 MapReduce 编程模型,可以处理海量数据,主要面向批处理。
系统会将海量数据分割为一个个小块分给 Map 任务,任务要输出 k - v 形式的数据,0~n条都可以。Reduce 任务会接收 Map 任务的输出。各个 Map 任务的输出,可能会有相同 key 的键值对,那么它们会被聚拢、排序,会以类似 k - list of v 的形式成为 Reduce 任务的输入。
2. HDFS 存储数据
HDFS(Hadoop Distributed File System),是 Hadoop 提供的分布式文件系统,有很好的扩展性和容错性,为海量数据提供存储支持。
3. 特点 参考
1. Hardware Failure
一个集群的硬件必然会有出错,HDFS 会包容这种错误,并依然可以正常运行,HDFS 目标是迅速找出问题,自动恢复
2. Streaming Data Access
HDFS 是为了高吞吐而生。不擅长低延迟、交互性的应用场景。HDFS 上面的应用使用流(streaming)来访问他们的数据集
3. Large Data Sets
单个集群就包含数百个节点
4. Simple Coherency Model
write-once-read-many access文件模型,不允许改变(append 、truncate除外),以保证一致性
5. “Moving Computation is Cheaper than Moving Data”
HDFS 要提供接口,使得应用可以把 computaion 放到距离数据存储更近的节点
6. Portability Across Heterogeneous Hardware and Software Platforms
跨异构硬件和软件平台的可移植性
4. 架构
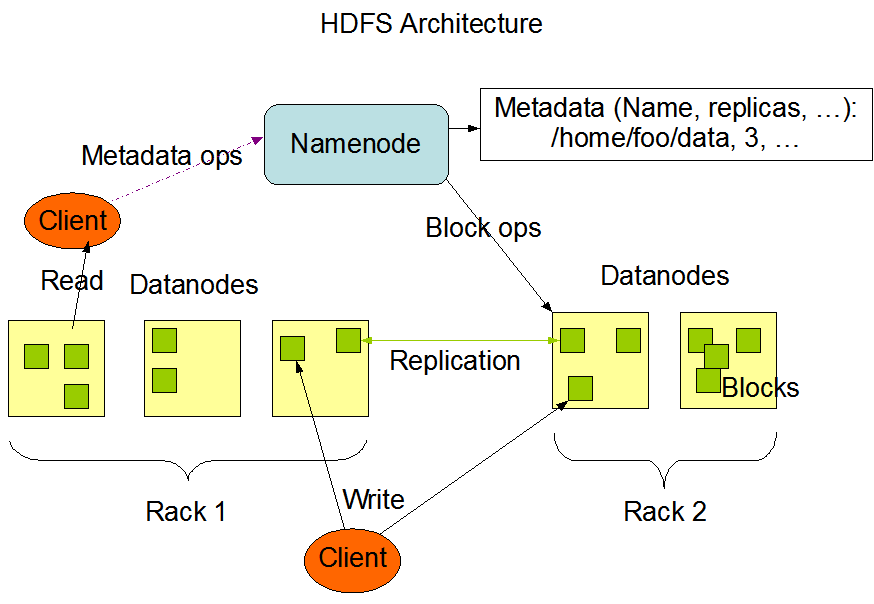
HDFS 是主存结构,单个 NameNode 管理着文件系统的 namespace 以及 Client 权限,多个 DataNode,管理存储节点上的数据。
单一的 NameNode 对整个HDFS上的metadata(元数据)负责,如果 NameNode 挂了,需要人工干预、重启。
3. YARN 负责集群的资源管理
YARN(Yet Another Resource Negotiator),是 Hadoop 生态中的资源调度器,可以管理一个 Hadoop 集群,并为各种类型的大数据任务分配计算资源。主要负责 资源管理(Resource Management) 和 任务调度、监控(Job Scheduling/Monitoring)。
1. 架构 参考
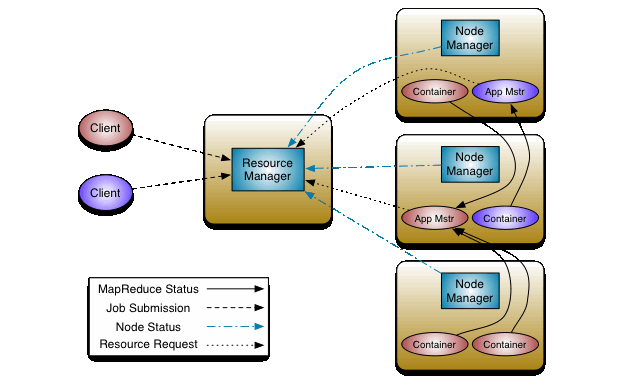
1. 整个系统一个:ResourceManager
负责整个系统的资源管理和分配。由2部分组成:Scheduler(调度器)、ApplicationsManager (ASM)。前者负责将资源分配给各种正在运行的应用程序,后者负责接受作业提交,协商执行程序的容器,并在失败时重启容器服务。
2. 每个应用一个:ApplicationMaster (App Mstr 或 AM)
框架特定的库,并负责与ResourceManager协商资源并与NodeManager一起执行和监视任务。
3. 每个节点一个:NodeManager (NM)
每台机器的框架代理,负责容器,监视其资源使用情况(cpu,内存,磁盘,网络),并将其报告给 ResourceManager/Scheduler
4. 图示箭头
- 每个
NM都要向RM发送本节点的情况(Node Status) - 左边2个
Client分别向RM提交Job (Job Submission) App Mstr向RM发送资源申请(Resource Request)- 每个
Container向App Mstr发送MapReduce Status(MapReduce 任务状态)
