1. 基本概念
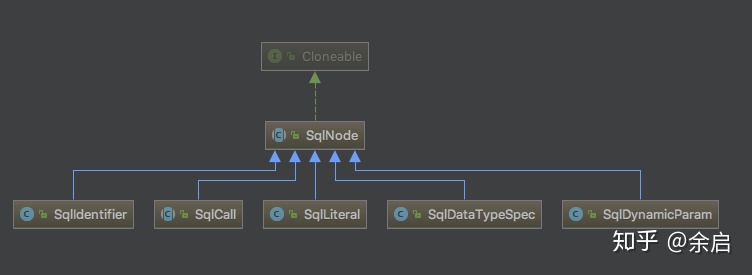
1. SqlNode
SqlNode 是 Calcite 中用于表达关系运算的中间数据结构
1 | -- 例如 |
其中:
SqlIdentifier:id, score, T 等SqlDataTypeSpec:intRexInputRef:idRexLiteral:常量表达式,如’hello’RexCall:函数表达式,如 cast(),包括SqlSelect、SqlDelete、SqlBasicCallSqlDynamicParam: ‘?’
2. 名词
| 名称 | 解释 | 作用 |
|---|---|---|
| SqlNode | SqlTree 中的 Node | SqlNode 在 SqlToRelConverter 中转化为 RelNode |
| RexNode | 表达式 | RexLiteral 是常量表达式,如“123”;RexCall 是函数表达式,如 cast(xx as xx);RexInputRef 输入,如 id |
| RelNode | 关系表达式(动词) | 常在执行计划中看到,如TableScan、Project、Sort、Join 等 |
| RelSubset | 带有同一 Trait 的 RelNode 集合 | |
| RelSet | RelSubset 集合 | |
| RelTrait | 特征 | RelNode 对应的特征,如 RelCollation 可能是 Project 中的排序特征 |
| TraitDef | 特征定义 | 定义了 Trait 对应的一些方法 |
| Convention | 转化特征 | 用于转化 RelNode,常见的有 SparkConvention,FlinkConvention |
| Literal | 常量 | |
| Planner | SQL计划 | 可用于解析、优化、执行 |
| Program | 程序 | 可根据 Rules 自行构建,作用和 Planner 类似 |
3. 名词释义
1. SqlNode
一个 select 语句包含 from 部分、where 部分、select 部分等,每一部分都表示一个 SqlNode。
SqlKind 是一个枚举类型,包含了各种 SqlNode 类型:SqlSelect、SqlIdentifier、SqlLiteral等
SqlSelect表示复杂SqlCallSqlIdentifier表示标识符,例如表名称、字段名SqlLiteral表示字面常量,一些具体的数字、字符SqlDataTypeSpec表示数据类型节点,如 CHAR、VARCHAR、DOUBLESqlNodeList表示包含多个同级别的 SqlNode
2. SqlCall
在 Calcite 中,所有的操作都是一个 SqlCall,如查询、删除、关联等,对应的查询条件等为 SqlCall 中的参数
SqlSelect查询 SqlCall,内部可以包含其他节点SqlDelete删除 SqlCall,内部可以包含其他节点SqlJoin关联 SqlCall,内部可以包含其他节点SqlBasicCall相比于其他,是简单的 SqlCall,表示的是一些基本的、简单的调用,例如聚合函数、比较函数等,其内部主要就是operands,也是 SqlNode 节点,但是都是一些基本的 SqlNode ,如 SqlIdentifier、SqlLiteral
3. RelNode 关系表达式
主要有 TableScan、Project、Sort、Join 等。如果SQL为查询的话,所有关系达式都可以在 SqlSelect 中找到,如:
- From 对应 TableScan、Join
- selectList 对应 Project
- orderBy、offset、fetch 对应着 Sort
- where 和 having 对应的 Filter
RelNode树
1 | LogicalProject |
4. RexNode 行表达式
如 RexLiteral(常量)、RexCall(函数)、RexInputRef(输入引用)等
5. Traits 转化特征
存在于 RelNode 中,目前有三种 Traits : Convention、RelCollation、RelDistribution。
Convention指的是改关系表达式所遵循的规范,如 SparkConvention、PigConvention、FlinkConvention,同一个关系表达式的所有输入必须含有相同的 Convention。可以通过 ConverterRule 将一个 Convention 转化成另一个 Convention。RelCollation指的是该关系表达式所定义数据的排序,比如说 LogicalSort 中如果 RelCollation 标识数据已经是排序好了,可以消除 LogicalSort。RelDistribution标识数据的分布特点
6. Rule 转化规则
可以将一个 RelNode 转化另一种 RelNode ,目前 Calcite 主要有两种 Rule:
- 直接继承
RelOptRule,这种类型的 Rule 主要作用是将一个关系表达式转化成等价的另一种表达式 - 继承
ConverterRule,将 RelNode 的 Convention 转化成另一种 Convention
7. Planners 优化器
主要有两种 HepPlanner 和 VolcanoPlanner,分别对应着 RBO 和 CBO 优化器
2. 架构与解析步骤
一般来说Calcite解析SQL有以下几步:
Parser。此步中 Calcite 通过 Java CC 将 SQL 解析成未经校验的 ASTValidate。该步骤主要作用是校证 Parser 步骤中的 AST 是否合法,如验证 SQL scheme、字段、函数等是否存在;SQL语句是否合法等。 此步完成之后就生成了 RelNode 树。Optimize。该步骤主要的作用优化 RelNode 树,并将其转化成物理执行计划。主要涉及 SQL 规则优化,如基于规则优化(RBO)及基于代价(CBO)优化;Optimze 这一步原则上来说是可选的, 通过 Validate 后的 RelNode 树已经可以直接转化物理执行计划,但现代的 SQL 解析器基本上都包括有这一步,目的是优化 SQL 执行计划。此步得到的结果为物理执行计划。Execute,即执行阶段。此阶段主要做的是将物理执行计划转化成可在特定的平台执行的程序。如 Hive 与 Flink 都在在此阶段将物理执行计划 CodeGen 生成相应的可执行代码。
