1. 数据建模与设计
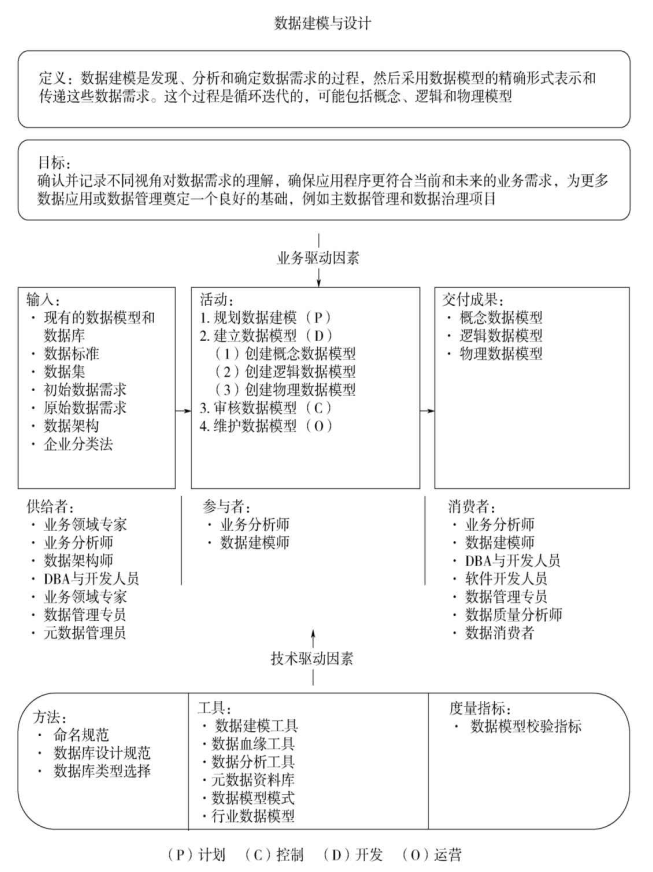
1. 数据模型及建模方法 6 种
常见数据模式有:关系模式、多维模式、面向对象模式、事实模式、时间序列模式、NoSQL 模式。
根据描述详细程度不同,每种模式可分为 3 种模型:概念模型、逻辑模型、物理模型。
2. 业务驱动因素
- 提供有关数据的通用词汇表
- 获取、记录组织内数据和系统的详细信息
- 在项目中作为主要的交流沟通工具
- 提供了应用定制、 整合, 甚至替换的起点
3. 数据建模目标和原则
确认和记录不同视角的理解有助于:
- 格式化:简洁定义,规范结构,防止异常
- 范围定义。 帮助解释数据上下文的边界
- 知识保留记录:为未来提供原始记录,助于更好的理解组织等,助于理解变更带来的影响。可被重复利用,帮助了解环境中的数据结构。建模师帮助他人理解信息蓝图。
4. 建模的数据类型
以下四类都属于 “静态数据”。部分 “动态数据” 也可以建模。例如,系统的方案,包括用于消息传递和基于事件的系统的协议和方案等。
- 类别信息,对事物分类或分配事物类型的数据,如颜色、型号
- 资源信息,实施操作流程所需的基本数据,如产品、客户。资源实体有时被称为参考数据
- 业务事件信息,在操作过程中创建的数据,如客户订单。事件实体有时被称为交易性业务数据
- 详细交易信息,通过销售系统、传感器生成,用于分析趋势,常成为大数据。
5. 数据模型组件
1. 实体
实体是一个组织收集信息的载体,实体实例是特定实体的具体化或取值
1. 实体的别名
- 关系模型:实体
- 维度模型:维度、事实表
- 面向对象模型:类、对象
- 基于时间模型:中心、卫星、链接
- 非关系型模型:文件、节点
- 概念模型:概念、术语
- 逻辑模型:实体
- 物理模型:表
2. 关系
实体之间的关联。
1. 关系的别名
- 关系模型:关系
- 维度模型:导航路径
- 非关系型模型:边界、链接
- 物理模型:约束、引用
2. 关系的基数
说明了一个实体和其他实体参与建立关系的数量。
- 一元关系:又称递归关系、自我引用关系,只包含一个实体
- 二元关系:涉及两个实体
- 三元关系:涉及三个实体
3. 属性
定义、 描述或度量实体某个方面的性质。属性可能包含域。属性在图中是在实体矩形内用列表描述。实体中属性的物理展现为表、视图、文档、图形或文件中的列、字段、标记或节点等。
标识符(Identifiers)也称为键,是唯一标识实体实例的一个或多个属性的集合。
1. 键的结构类型
- 单一键:唯一标识实体实例的一个属性。
- 代理键: 也是单一键,表的唯一标识符,通常是一个计数符,由系统自动生成,一个整数,含义与数值无关,技术性,不应对用户可见。
- 组合键:一组由两个或多个属性组成的集合,一起达到唯一标识一个实体实例。
- 复合键: 包含一个组织键和至少一个其他单一键、 组合键或非键属性
2. 键的功能类型
- 超键:唯一标识实体实例的任何属性集。
- 候选键:标识实体实例的最小属性集合,可能包含一个或多个属性。最小意味着候选键的任意子集都无法唯一标识实体实例。一个实体可以有多个候选键。候选键可以是业务键(自然键)。
- 业务键:业务专业人员用于检索单个实体实例的一个或多个属性。业务键和代理键是互斥关系。
- 主键:被选择为实体唯一标识符的候选键。
- 备用键:是一个候选键,虽唯一,但没有被选为主键,可用于查找特定实体实例
4. 域
某一属性可被赋予的全部可能取值。如属性为性别,域值就为男和女。
- 它提供一种将属性特征标准化的方法
- 域中所有的值都为有效的值,不在域中的值被称为无效的值
- 属性中不应当含有其指定的域以外的值
- 可以附加的规则对域进行限制,限制规则称为约束
6. 数据建模的方法
1. 关系建模
关系模型设计的目的是精确的表达业务数据,消除冗余,适合设计操作型的系统
2. 维度建模
维度建模为了优化海量数据的查询和分析,专注于特定业务流程的业务问题。
- 事实表:事实表中的行对应于特定的数值型度量值,如金额。事实表占据了数据中大部分空间,且有大量的行
- 维度表:表示业务的重要对象,主要留住文字描述。维度是事实表的入口点或链接。充当查询或报表约束的主要来源。高度反范式的,占总数的 10% 左右。各个维度在每一行都有一个唯一的标识符,主要是代理键和自然键。维度也有些属性。渐变类的维度根据变化的速率和类型来管理变化,主要变化有覆盖、新行、新列。
- 雪花模型(Snowflaking):将星型模型中的平面、单表、维度结构规范为相应的组件层次结构或网络结构。
- 粒度:事实表中单行数据的含义或描述, 是每行都有的最详细信息。 关键步骤之一。
- 一致性维度:基于整个组织。 一致性事实: 使用跨多个数据集市的标准化术语。
3. 面向对象
UML 统一建模语言
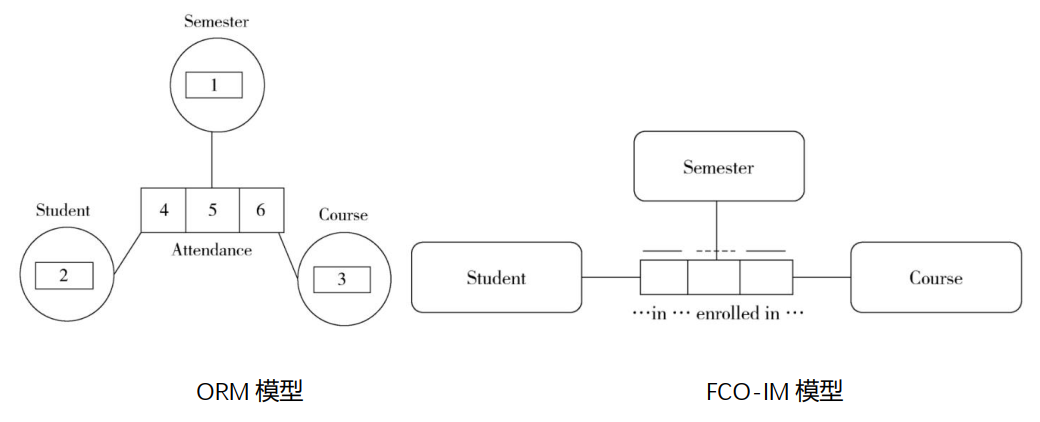
4. 基于事实的建模
- 对象角色建模:ORM、ORM2
- 完全面向通信的建模:FCO-IM
5. 基于时间的数据模型
1. 数据拱顶
数据拱顶一组支持一个或多个业务功能领域,面向细节、基于时间且唯一链接的规范化表。数据拱顶模型是一种混合方式, 综合了第三范(3NF)和星型模式的优点。
数据拱顶模型专门为满足企业数据仓库的需求而设计的。有 3 种类型的实体:
- 中心表
- 链接表
- 卫星表
设计的重点是业务的功能领域,中心表代表业务主键,链接表定义了中心表之间的事务集成,卫星表定义了中心表主键的语境信息。
2. 锚建模
锚模型(Anchor Model)适合信息的结构和内容都随时间发生变化的情况。它有四个基本建模概念:
- 锚:锚模拟的是实体和事件
- 属性:属性模拟了锚的特征
- 连接:连接表示了锚之间的关系
- 节点:节点模拟共享的属性
6. 非关系型数据库
非关系型数据库(NoSQL)是基于非关系技术构建的数据库的统称。通常有4类NoSQL数据库:
- 文档数据库
- 键值数据库
- 列数据库
- 图数据库
6. 数据模型级别
- 概念数据模型(CDM):企业的 “真实世界” 视图,代表企业当前的最佳模式或经营方式,用一系列相关主题域的集合来描述概要数据需求
- 外模式:即逻辑数据模型(LDM),对数据需求的详细描述
- 内模式:即物理数据模型(PDM),描述了一种详细的技术解决方案,通常以逻辑数据模型为基础
7. 数据模型和设计活动(见语境关系图)
规划数据建模:交付成果:图表、定义、争议和悬而未决的问题、血缘关系
建立数据建模:正向工程是指从需求开始构建新应用程序的过程,如下3步,逆向工程则3步反过来:
- 概念数据模型建模:选择模型类型、选择表示方法、完成初始概念模型、收集组织中最高级的概念(名称)、收集与这些概念有关的活动(动词)、合并企业术语、获取签署
- 逻辑数据模型建模:分析信息需求、分析现有文档、添加关联实体、添加属性、指定域、指定键
- 物理数据模型建模:解决逻辑抽象、添加属性细节、添加参考数据对象、指定代理键、逆规范化、建立索引、分区、创建视图
审核数据建模:通过持续改进实践来控制模型质量
维护数据建模:保持最新状态
8. 其他概念
1. 模型
- 概念数据模型(Conceptual Data Model,CDM)是用一系列相关主题域的集合来描述概要数据需求
- 逻辑数据模型(Logical Data Model,LDM)是对数据需求的详细描述,通常用于支持特定用法的语境中(如应用需求)
- 物理数据模型(Physical Data Model,PDM)描述了一种详细的技术解决方案,通常以逻辑数据模型为基础,与某一类系统硬件、软件和网络工具相匹配
2. 规范化和逆规范化
- 逆规范化(Denormalization)是将符合范式规则的逻辑数据模型经过慎重考虑后,转换成一些带冗余数据的物理表。
- 规范化(Normalization)的基本目标是保证每个属性只在一个位置出现,以消除冗余。
- 第一范式(1NF):每个实体都有一个有效的主键,每个属性都依赖于键
- 第二范式(2NF):每个实体都有最小的主键,每个属性都依赖于完整的主键
- 第三范式(3NF):每一实体都没有隐藏的主键,属性都不依赖于键值外的任何属性(仅依赖于完整的主键)。模型的规范化通常要求达到第三范式。
- Boyce/Codd 范式(BCNF):解决交叉的复合候选键问题。候选键是主键或备用键。
- 第四范式(4NF):将所有三元关系分解为二元关系,直到这些关系不可再分
- 第五范式(5NF):将实体内部的依赖关系分解为二元关系,所有联结依赖部分主键
3. 抽象化
抽象化(Abstraction)就是将细节移除,这样可以在更广泛的情况下扩展适用性,同时保留概念或主题的重要和本质属性。
- 泛化:将实体公共属性和关系分组为超类实体
- 特化:将实体中的分区属性分类为子类实体,通常基于实体实例中的属性值
4. 数据库设计最佳实践
PRISM 设计原则:
- 性能和易用性(Performance and Ease of Use)
- 可重用性(Reusability)
- 完整性(Integrity)
- 安全性(Security)
- 可维护性(Maintainability)
5. 建立数据库模型 2 种方式
- 正向工程:指从需求开始构建新应用程序的过程
- 逆向工程:记录现有数据库的过程
