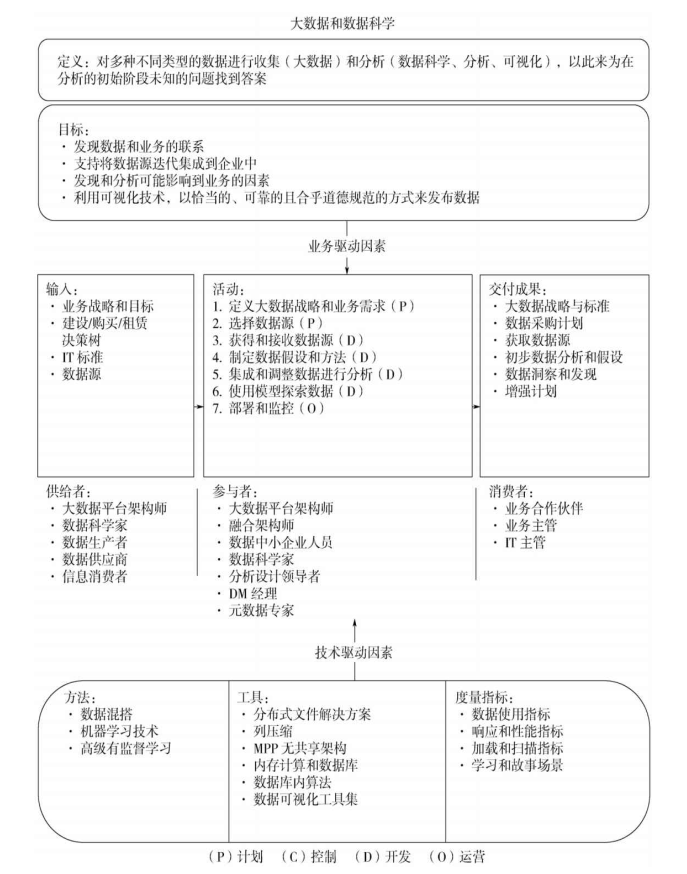
1. 大数据和数据科学
1. 原则
组织应仔细管理与大数据源相关的元数据, 以便对数据文件及其来源和价值进行准确的清单管理。
2. 数据科学依赖
- 丰富的数据源
- 信息组织和分析
- 信息交付
- 展示发现和数据洞察
3. 大数据
大数据含义的特征,早期 3V 以及新增:
- 数据量大(Volume)
- 数据更新快(Velocity)
- 数据类型多样/可变(Variety)
- 数据黏度大(Viscosity)
- 数据波动性大(Volatility)
- 数据准确性低(Veracity)
4. 数据湖
数据湖是一种可以提取、存储、评估和分析不同类型和结构海量数据的环境,可供多种场景使用。风险在它可能很快会变成数据沼泽,杂乱、不干净、不一致,因此数据被摄取时需要对元数据进行管理。
- 数据科学家可以挖掘和分析数据的环境
- 原始数据的集中存储区域,只需很少量的转换(如果需要的话)
- 数据仓库明细历史数据的备用存储区域
- 信息记录的在线归档
- 可以通过自动化的模型识别提取流数据的环境
5. 机器学习
机器学习(Machine Learning)探索了学习算法的构建和研究,它可以被视为无监督学习和监督学习方法的结合。算法一般分为三种类型:
- 监督学习(Supervised learning):基于通用规则
- 无监督学习(Unsupervised learning):基于找到的那些隐藏的规律(数据挖掘)
- 强化学习(Reinforcement learning):基于目标的实现(如在国际象棋中击败对手)
6. 数据挖掘
数据挖掘(Data mining)是一种特殊的分析方法,它使用各种算法揭示数据中的规律。它是机器学习的一个分支。数据和文本挖掘使用的技术:
- 剖析(Profiling):描述人群典型特征
- 数据缩减(Data reduction):用较小的数据集来替换大数据集
- 关联(Association)
- 聚类(Clustering):根据共享特征聚合
- 自组织映射(Self-organizing maps):降维
