wiki
本章节知识点会涉及考试中的各种题型,上午的客观题占 6 分,下午的程序设计与设计模式的结合往往是最后一道大题。
1. 程序语言的基本概念
1. 低级语言与高级语言
- 低级语言:汇编
- 高级语言:常见的有 Java、C、C++、PHP、Python、Delphi 等
2. 翻译形式
- 源程序:用汇编或高级语言编写的程序,其不能直接在计算机上执行
翻译形式有:
- 汇编:将汇编程序翻译成目标程序再执行
- 解释:直接解释执行源程序或将源程序翻译成中间代码再执行,解释程序和源程序都参与目标程序执行
- 编译:将源程序翻译成目标语言程序再执行,编译程序和源程序不参与目标程序执行
3. 程序设计语言的定义
语法、语义、语用。
4. 程序设计语言的分类
- 过程式(命令式和结构化):FORTRAN、Pascal、C
- 面向对象:Simula、Smalltalk、C++、Objective C、Java、Python
- 函数式:lisp、python、scala
- 逻辑型:Prolog
- 脚本语言:shell、bat、js、python
2. 程序设计的基本成分
程序语言的基本成分包括数据、运算、控制、传输等。
- 数据成分:常量和变量、全局量和局部量、数据类型
- 运算成分:算式运算、关系运算、逻辑运算
- 控制成分:顺序结构、选择结构、循环结构(while、do-while)
- 函数:定义、声明、调用(值调用、引用调用)
3. 汇编程序基本原理
汇编语言是为特定的计算机或计算机系统设计的面向机器的符号化的程序设计语言。
汇编语言源程序由若干条语句组成,语句可以分为三类:
- 指令语句:汇编后生成相应机器码
- 伪指令语句:在汇编源程序中使用,如存储地址分配,最后不生成机器码
- 宏指令语句:将多次使用的程序定义成宏
汇编程序一般需要两次扫描源程序才能完成翻译过程:
- 第一次扫描:检查语法错误,确定符号名字;建立使用的全部符号名字表;每一符号名字后跟一对应值(地址或数)。
- 第二次扫描:在第一次扫描的基础上,将符号地址转换成真地址(代真);利用操作码表将助记符转换成相应的目标码。
4. 编译程序基本原理
编译程序的工作过程分为六个阶段:
- 词法分析:扫描源程序,识别出单词,如关键字、运算符等,输出二元组,即单词和单词自身的值
- 语法分析:将单词划分为语法单位,如表达式、程序等,正确时生成语法树,否则指出错误,并提出诊断信息
- 语义分析:检查静态语义错误,收集类型信息,如类型不匹配错误
- 中间代码生成:生成与机器无关的记号系统,如四元式,形式为
(运算符,运算对象1,运算对象2,运算结果) - 代码优化:原则是等价变换原则
- 目标代码生成:把中间代码转换成特定机器上的绝对指令代码
1. 文法 G={Vt, Vn, S, P}
- Vt 是一个非空有限集合的符号,它的每个元素称为终结符号
- Vn 是一个非空有限集合的符号,它的每个元素称为非终结符号
- S 称为文法 G 的开始符号
- P 是一个非空有限集合,它的元素称为产生式
文法分类:
- 0 型文法:短语文法,是递归可枚举集
- 1 型文法:又称为上下文有关文法
- 2 型文法:又称为上下文无关文法,程序设计语言绝大多数语法规则可以采用它描述
- 3 型文法:又称为正规文法,使用最多
2. 文法分析
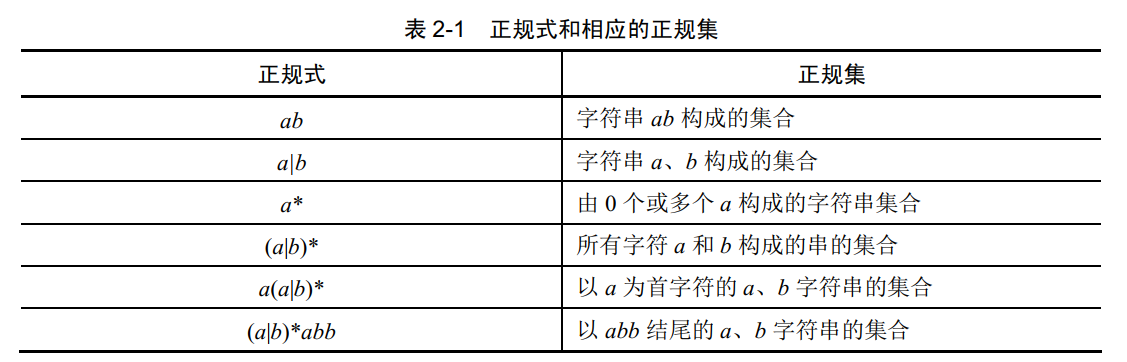
1. 正规表达式和正规集
对于字母表 Σ,其上的正规式及其表示的正规集可以递归定义如下:
ε是一个正规式,它表示集合L(ε)={ε}- 若
a是 Σ 上的字符,则 a 是一个正规式,它所表示的正规集为{a} - 若正规式
r和s分别表示正规集L(r)和L(s),则:r|s是正规式,表示集合L(r)∪L(s)r·s是正规式,表示集合L(r)L(s)r*是正规式,表示集合(L(r))*(r)是正规式,表示集合L(r)
仅由有限次地使用上述三个步骤定义的表达式才是 Σ 上的正规式,其中运算符 |、·、* 分别称为 “或”、“连接”、“闭包”。在正规式的书写中,连接运算符 · 可省略。运算符的优先级从高到低的顺序排列为*、·、|。
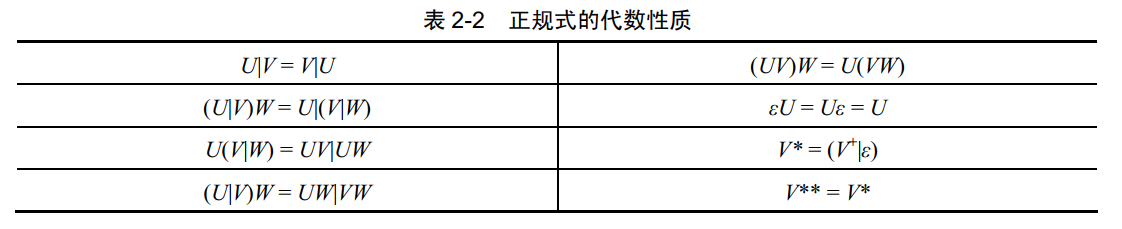
若两个正规式表示的正规集相同,则认为二者等价,两个等价的正规式 U 和 V 记为 U=V。正规式的代数性质如下表:
2. 有限自动机
计算机控制系统的控制程序具有有限状态自动机(Finite Automata, FA)的特征,可以用有限状态机理论来描述。
有限状态机可以准确地识别正规集。
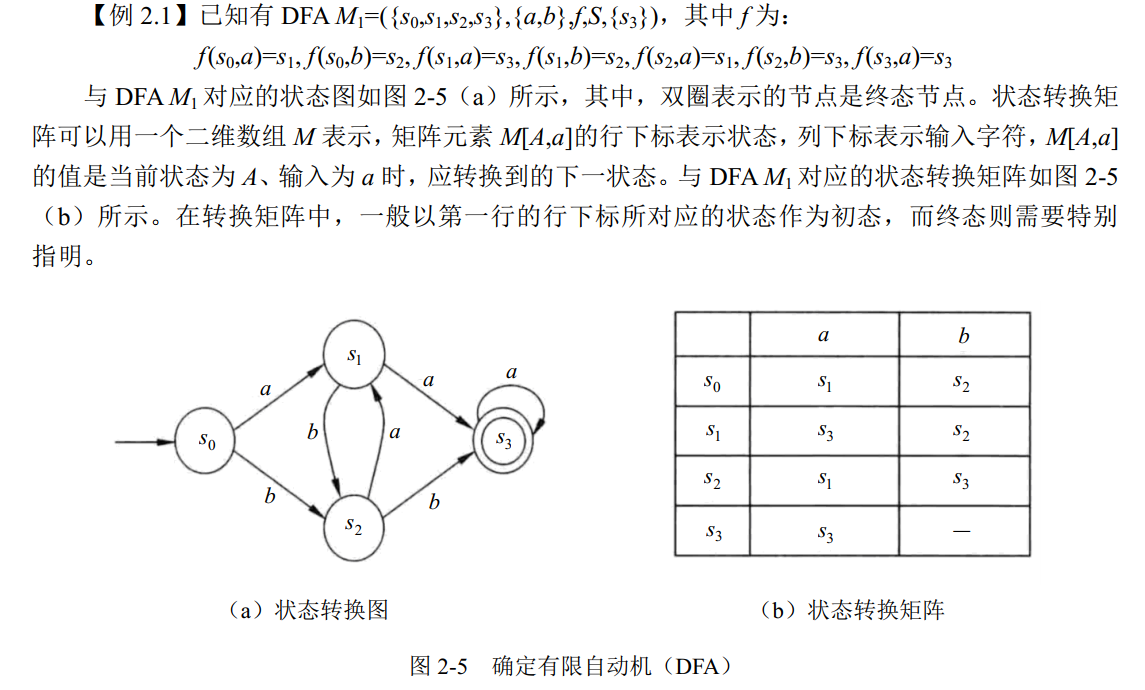
1. 确定有限自动机(DFA)
自动机的每个状态都有对字母表中所有符号的转移。一个确定的有限自动机是个五元组 (S,Σ,f,s0,Z),其中:
S是一个有限集,其每个元素称为一个状态Σ是一个有穷字母表,其每个元素称为一个输入字符f是S×Σ → S上的单值部分映像。f(A,a)=Q表示当前状态为 A,输入为 a 时,将转换到下一状态 Q,并称 Q 为 A 的一个后继状态s0∈S,是唯一的一个开始状态Z是非空的终止状态集合,Z⊆S。
一个 DFA 可以用两种直观的方式表示:状态转换图、状态转换矩阵。
- 状态转换图:简称转换图,是一个有向图。
- 节点:表示一个状态
- 有向弧:表示一个转换函数
- 若转换函数为
f(A,a)=Q,则该有向弧从节点 A 出发,进入节点 Q,字符 a 是弧上的标记
- 状态转换矩阵:矩阵方式描述,行下标表示状态,列下标表示输入字符
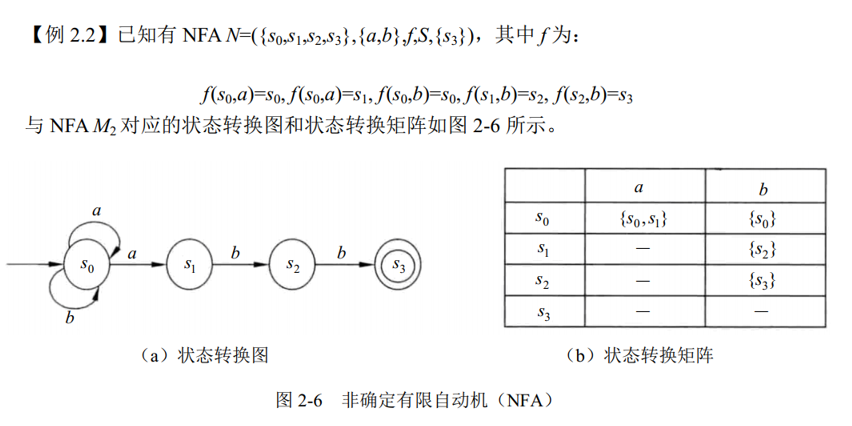
2. 非确定有限自动机(NFA)
自动机的状态对字母表中的每个符号可以有转移,也可以没有转移,对一个符号甚至可以有多个转移。
一个不确定的有限自动机也是一个五元组,它与确定有限自动机的区别如下:
f是S×Σ → 2S上的映像。对于S中的一个给定状态及输入符号,返回一个状态的集合,即当前状态的后继状态不一定是唯一确定的- 有向弧上的标记可以是
ε
3. NFA 转换 DFA
DFA 是 NFA 特例,任何 NFA 都可以转换为 DFA。
3. 正规式与有限自动机之间的转换
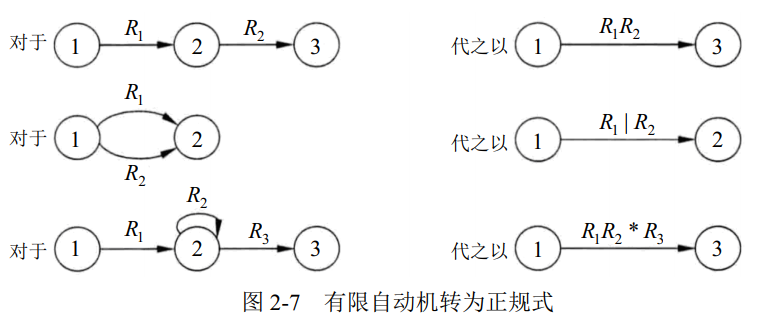
有限自动机转为正规式的过程如下:
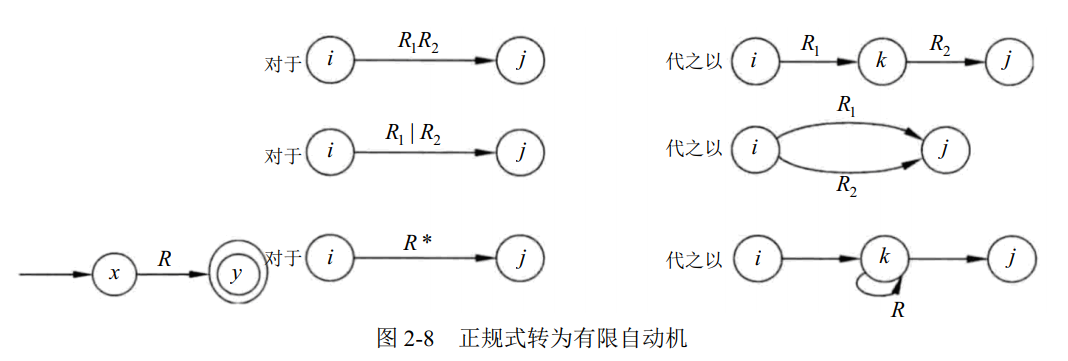
正规式转为有限自动机的过程如下:
4. 语法制导翻译和中间代码生成
程序设计语言的语义分为静态和动态语义,应用最广的静态语义分析方法是语法制导翻译。
中间代码常用的有:后缀式、树式、三元式、四元式等:
- 后缀式:也称逆波兰式,它不使用括号,并把运算符写在对象后面,如
a+b写为ab+,x:=(a+b)/(c+d)写成xab+cd+/:=。 - 树式:符号做根,形似中序遍历
- 三元式:由运算符 OP、第一运算对象 ARG1 、第二运算对象 ARG2 组成,如
x:=(a+b)/(c+d)三元式为①(+,a,b) ②(+,c,d) ③(/,①,②) ④(:=,③,x)。 - 四元式:普遍采用,三元式增加结果 RESULT,用临时变量表示,如
x:=(a+b)/(c+d)三元式为①(+,a,b,t1) ②(+,c,d,t2) ③(/,t1,t2,t3) ④(:=,t3,_,x)。
5. 解释程序基本原理
解释程序是另一种语言处理程序,在词法、语法和语义分析方面与编译程序的工作原理基本相同,但是在运行用户程序时,它直接执行源程序或源程序的内部形式。
解释程序不产生源程序的目标程序,这是它和编译程序的主要区别。
